How To Write Parquet File In Python
Following are the popular compression formats. Conda install python-snappy conda install fastparquet.

Parquet My Big Data World
Df pdread_csvdataus_presidentscsv dfto_parquettmpus_presidentsparquet write_parquet_file This code writes out the data to a tmpus_presidentsparquet file.

How to write parquet file in python. In this example snippet we are reading data from an apache parquet file we have written before. 29032020 import pandas as pd def write_parquet_file. DataFrameto_parquetpathNone engineauto compressionsnappy indexNone partition_colsNone storage_optionsNone kwargs source.
My_integer ingest_data input_data schema field_aliases Writing Parquet Files. Make sure you have installed the following. Pip install petl pip install pandas Build an ETL App for Parquet Data in Python.
Now lets create a parquet file from PySpark DataFrame by calling the parquet function of DataFrameWriter class. You can choose different parquet backends and have the option of compression. When you write a DataFrame to parquet file it automatically preserves column names and their data types.
Below is the example. 27032017 Here we are doing all these operations in spark interactive shell so we need to use. Data_page_size to control the approximate size of encoded data pages within a column chunk.
Parquet_file dataparquet open parquet_file w Then use pandasto_parquet this function requires either the fastparquet or pyarrow library parquet_dfto_parquetparquet_file Then use pandasread_parquet to get a dataframe. Snappy default requires no argument gzip. After installing the CData Parquet Connector follow the procedure below to install the other required modules and start accessing Parquet through Python objects.
ParquetDatasets beget Tables which beget pandasDataFrames. 30032021 Now we can write a few lines of Python code to read Parquet. Connect to your local Parquet files by setting the URI connection property to the location of the Parquet file.
06022019 Similar to write DataFrameReader provides parquet function sparkreadparquet to read the parquet files and creates a Spark DataFrame. Parquet with Snappy compression. Import pandas as pd import snappy import fastparquet.
Below code snippet shows creating DataFrame with sample data and write data in parquet file format and read the parquet file that was written in both Python ans Scala. 13032021 To load records from a one or more partitions of a Parquet dataset using PyArrow based on their partition keys we create an instance of the pyarrowparquetParquetDataset using the filters argument with a tuple filter inside of a list more on this below. Version the Parquet format version to use whether 10 for compatibility with older readers or 20 to unlock more recent features.
If you want to follow along I used a sample file from GitHub. Pyspark Write DataFrame to Parquet file format. Upload a file by calling the DataLakeFileClientappend_data method.
Make sure to complete the upload by calling the DataLakeFileClientflush_data method. 17022021 First create a file reference in the target directory by creating an instance of the DataLakeFileClient class. Write a DataFrame to the binary parquet format.
Each part file Pyspark creates has the parquet file extension. 12092020 Set name and python version upload your fresh downloaded zip file and press create to create the layer. Val parqDF spark.
Go to your Lambda and select your. Parquet file writing options. 14092017 from json2parquet import load_json ingest_data write_parquet write_parquet_dataset Loading JSON to a PyArrow RecordBatch schema is optional as above load_json input_filename schema Working with a list of dictionaries ingest_data input_data schema Working with a list of dictionaries and custom field names field_aliases my_column.
Use the pip utility to install the required modules and frameworks. Write_table has a number of options to control various settings when writing a Parquet file. 7 rows 01052020 The to_parquet function is used to write a DataFrame to the binary.
This example uploads a text file to a directory named my-directory. Parquet files can be further compressed while writing. This function writes the dataframe as a parquet file.
09122016 Second write the table into parquet file say file_nameparquet Parquet with Brotli compression pqwrite_tabletable file_nameparquet NOTE. Considering the parquet file named data. This currently defaults to 1MB.
Lets read the Parquet data into a Pandas DataFrame and view the results. Assume you have the following pandas df. 04102015 using fastparquet you can write a pandas df to parquet either with snappy or gzip compression as follows.

Spark Read And Write Apache Parquet Sparkbyexamples

How To Move Compressed Parquet File Using Adf Or Databricks Microsoft Q A
How To Load A Parquet File Into A Hive Table Using Spark Stack Overflow

Pyspark Read And Write Parquet File Sparkbyexamples

How To Load Parquet File Into Snowflake Table Sparkbyexamples

How To Read Parquet File From Aws S3 Directly Into Pandas Using Python Boto3 Youtube
Parquet File Format Gm Rkb
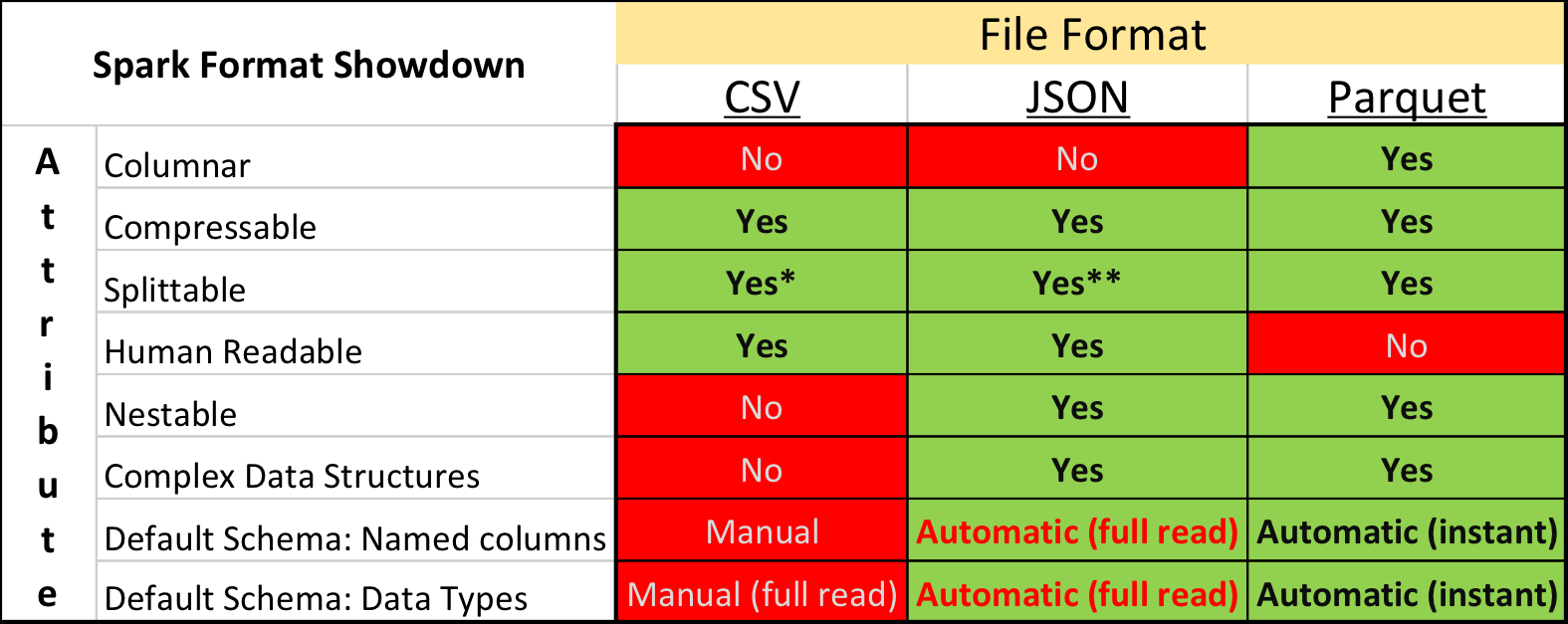

How To Generate Parquet Files In Java The Tech Check

Parquet File Read And Write And Merge Small Parquet Files Programmer Sought
{kind=link}
Post a Comment for "How To Write Parquet File In Python"